Deepfakes, impersonation and identity verification in the AI era
A defensive analysis of deepfakes, synthetic documents and AI identity verification: risks, KYC, detection, liveness and human review.
On my thePalms channel I published a video titled The dark side of AI: deepfakes, identity impersonation and the rise of OnlyFake. It was a short video from February 2024, but the topic has become increasingly important: AI no longer only generates text or funny images. It can also weaken systems that used to trust simple visual proof.
The core idea was simple: if a platform lets someone open an account, verify identity or recover access with a photo of an ID document and a selfie, the system becomes fragile when models can generate realistic documents, clone faces, simulate voices or create videos where someone appears to say something they never said.
This article does not explain how to create deepfakes or fake documents. The focus is defensive: what the risks are, why a single image is no longer enough and how I would design stronger identity verification.
Direct answer
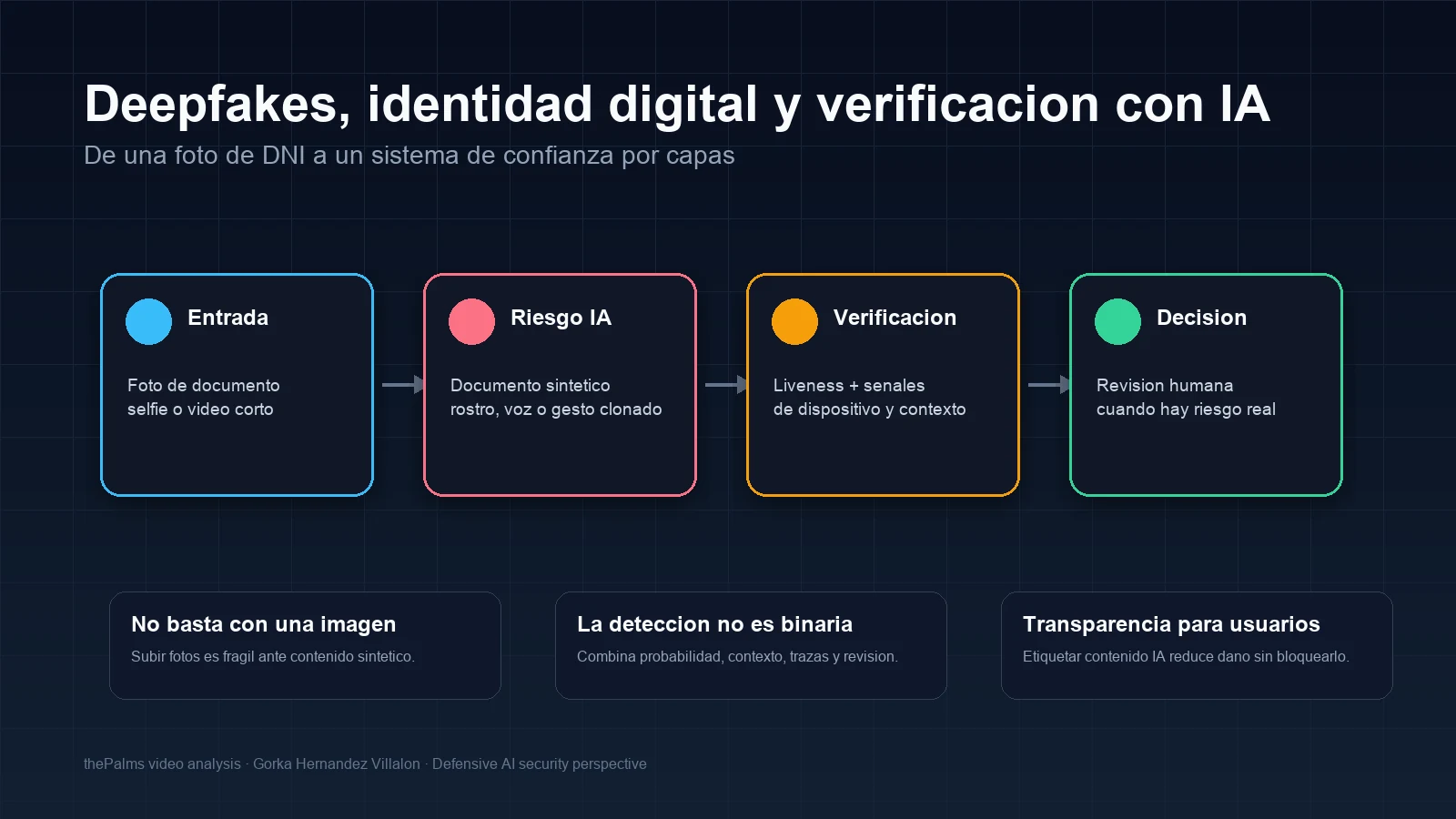
Deepfakes and synthetic documents turn identity verification into a layered security problem. It is no longer enough to check whether a photo "looks real". A serious system should combine document authenticity, liveness, device signals, temporal consistency, behaviour, manipulation detection, traceability and human review for risky cases.
The core map is:
| Risk | Reasonable defence |
|---|---|
| Generated or manipulated document | Document verification, metadata, consistency and fraud checks |
| Synthetic selfie | Active/passive liveness and presentation attack detection |
| Cloned voice or video | Provenance, multimodal analysis and origin context |
| Account created with stolen identity | Device signals, reputation, behaviour and human escalation |
| Viral false content | Labelling, provenance, context and user education |
Detection should not work like a magic "real or fake" button. It should produce a risk signal that is combined with other evidence.
Why I recorded that video
In the video I discussed tools capable of generating realistic-looking document images. The worrying part was not only the document itself, but the combination of signals:
- public data about a person;
- a photo of their face;
- a generated document image;
- a simulated selfie or scene;
- a platform that accepts overly simple remote checks.
The problem appears when an identity flow is designed for older attacks. A few years ago, asking for a photo of an ID document could look like a reasonable barrier for many services. Today, that barrier alone is weak if attackers can synthesize convincing images.
Fraud does not need to be perfect. It only needs to be good enough to pass low-quality automated checks or overload manual review teams.
A deepfake is not only a fake video
When people hear "deepfake", they often think of a video of a famous person saying something odd. That exists, and in the video I mentioned public-image fraud and fake content used for scams. But the concept is broader.
In practice, the risk includes:
- synthetic document images;
- generated or manipulated selfies;
- voice cloning for calls;
- fake lip-synced videos;
- interviews or messages generated from deceased people;
- avatars imitating real people;
- prepared screenshots that look like authentic evidence.
The boundary between entertainment, creative expression, fraud and impersonation depends on context. A clearly labelled AI dub may be harmless. An unlabelled video attributing false statements to a person can harm reputation, enable scams or trigger unfair decisions.
Why simple KYC breaks
KYC means Know Your Customer: processes used to verify who a person is before opening an account, moving money, subscribing to a sensitive service or accessing certain systems.
The issue is that many remote flows are too simple:
- upload a document photo;
- upload a selfie;
- compare the face with the document;
- approve if the similarity looks high enough.
That flow has value, but it should not be the only barrier. If the inputs can be synthetic, the system needs to verify more than pixels.
A stronger design would ask:
- where did the image come from?
- are there signs of real capture or editing?
- is the document internally consistent?
- is the face alive or a replay?
- does the device have suspicious history?
- does the behaviour match a normal onboarding flow?
- are there inconsistencies in location, time, language or pattern?
- which decisions require human review?
In digital identity, one strong-looking piece of evidence is rarely enough. What works is the accumulation of independent evidence.
Detector and anti-detector: the inevitable cycle
In the video I said that if an AI can generate something dangerous, another AI should detect whether that thing was AI-generated. The intuition is still valid, but I would phrase it more carefully today: detection is necessary, but not sufficient.
There is a continuous cycle:
- a generative technique appears;
- a detector is trained;
- generators learn to avoid detectable patterns;
- the detector improves;
- attackers change the format, compression, channel or context.
That is why I would not trust one detector as the whole defence. I would treat it as one risk signal inside a broader decision system.
Layered verification
If I had to design a remote identity anti-fraud system, I would split it into layers:
| Layer | Goal |
|---|---|
| Document | Validate format, consistency, quality and manipulation signals |
| Biometrics | Compare face while storing no more data than needed |
| Liveness | Confirm the presence of a live person, not a replayed photo or video |
| Device | Detect automation, emulators, suspicious VPNs or poor reputation |
| Context | Review country, time, language, behaviour and session consistency |
| Risk | Combine signals and decide approval, rejection or review |
| Audit | Keep proportionate traces with privacy and limited retention |
The NIST SP 800-63A digital identity guideline works with assurance levels, evidence, fraud mitigation and controls such as presentation attack detection when biometric characteristics are collected remotely. It is not a magic checklist, but it is a useful reference: identity is not proven with one photo; it is evaluated with assurance proportional to risk.
Labelling and transparency
Another point from the video was my idea that platforms should detect and warn when content is AI-generated. Not necessarily delete everything, but inform the user.
This matches where regulation is moving. The EU AI Act includes transparency obligations for generated or manipulated content that can appear authentic, especially image, audio or video. The logic is healthy: if something looks real but was artificially created, the user should have context.
Labelling does not solve every attack. Fraudsters can remove labels, crop media or forward screenshots. But it helps create norms: synthetic content is not bad by default; hiding its origin when it can cause harm is the dangerous part.
What an individual can do
This is not only an enterprise problem. Anyone can reduce risk:
- do not publish photos of identity documents;
- avoid uploading unnecessary selfies to questionable services;
- enable two-factor authentication on email, banking and social accounts;
- distrust urgent audio or video messages asking for money;
- verify unusual requests through another channel;
- limit public personal information that can be reused;
- use banking alerts and review transactions;
- report impersonation accounts.
The FTC has warned about scams where AI improves family-emergency fraud, including voice cloning. The practical rule is simple: the more emotional and urgent a message is, the more important it is to verify through another channel.
Why this topic matters to me as a developer
This topic connects strongly with how I think about AI systems. A model can generate, classify or detect, but the secure product is in the architecture:
- what data it accepts;
- which evidence it keeps;
- which decisions it automates;
- when it calls a human;
- what it explains to the user;
- what it logs without invading privacy;
- how it avoids unfairly blocking someone after a false positive.
It is the same criterion I apply to LLM automations: the model should not be the absolute judge. It should live inside a flow with rules, permissions, traces, thresholds and human review. I also cover this in security and privacy for enterprise AI agents and OSINT with LLMs and verifiable evidence.
Conclusion
The message from the video still holds: generative AI forces us to redesign how we trust images, voices and documents. What once looked like enough visual evidence can now be a synthetic input.
The answer is not to ban all AI or believe that one detector will solve the problem. The answer is to design layered trust systems: evidence, liveness, context, detection, transparency, human review and privacy.
Deepfakes are powerful technology. The challenge is not only detecting them, but building products where a fake image cannot easily become a fake identity.